
A native multi-model database from the ground up, supporting key/value, document and graph models. You can model your data in a very flexible way.
ArangoDB is a native multi-model database. Multi-model because ArangoDB provides the capabilities of a graph database, a document database, a key-value store in one C++ core. ArangoDB is native, because users can use and freely combine all supported data models even in a single query.
Another huge addition to ArangoDB’s capabilities is the new full-text search and ranking engine – ArangoSearch. ArangoSearch can be used in standalone fashion or be combined with graph traversals, geo queries, aggregations or any other supported access pattern.
Foundational to the native multi-model in ArangoDB is the flexibility of JSON. Users can store arbitrary complex data and even leverage nested properties in ArangoDB.
All data in ArangoDB is stored as JSON documents and similarly structured documents that can be pooled into collections—similar to a table in relational databases.

ArangoDB can be used as a transactional document store. Data can be queried using AQL, the ArangoDB Query Language.
AQL supports CRUD, aggregations, complex filter conditions, secondary indexes and real JOIN operations.
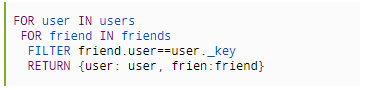

The graph capabilities of ArangoDB are very similar to a property graph database. For each document, a unique _id attribute is stored automatically. To build a relation (i.e., an edge) between two documents (i.e., vertices), both _id attributes are stored in a special edge document known as _from and _to attributes, forming a directed connection between two arbitrary vertices. Edges are then stored in a special edge collection.
ArangoDB enables efficient and scalable graph query performance by using a special hash index on _from and _to attributes (i.e., an edge index).
Vertices and edges are both full JSON documents and can hold arbitrary data. By this approach, ArangoDB is one of the few graph databases capable of horizontal scaling.

ArangoDB provides a broad spectrum of graph database features: graph traversals, shortest_path, pattern matching and distributed graph processing via Pregel.
Users can also take the result of a JOIN operation, geospatial query, text search or any other access pattern as a starting point for further graph analysis and vice versa – all in one query, if needed. This is an advantage of a native multi-model database like ArangoDB.
A graph can be visualized and manipulated directly within the ArangoDB WebUI. The WebUI provides many configurations for displaying edges and vertices.
ArangoSearch is a natively integrated, C++ based full-text search and similarity ranking engine. Search uses a special type of materialized view to provide full-text search across multiple collections at once. Within the definition of a view type arangosearch, you specify entire collections or individual fields to be covered by an inverted index with one or more general text analyzers. The view concept is currently exclusive to ArangoSearch, more general views (SQL like views, materialized views) may be introduced with later versions of ArangoDB.

In its current version, results are scored and ranked internally by using the BM25 or TFDIF algorithms. This can be configured by the user.
With the current version of ArangoSearch, users can already perform a broad spectrum of queries:
· Relevance-based matching;
· Phrase and prefix matching;
· Complex searches with boolean operators; and
· Relevance tuning on runtime.
ArangoSearch also provides language analyzers for twelve common languages including English, Chinese, German, Dutch, Spanish and French. Search queries can be executed against data sharded to an ArangoDB cluster.
ArangoDB also provides the characteristics of a modern, distributed key/value store. By just storing the document key and a value within a JSON document, some typical key/value operations like CRUD or range queries can be performed efficiently.
To support all the other data models natively, ArangoDB has to store more attributes compared to a “classical” key/value database. Due to this additional overhead, we don’t recommend ArangoDB for key/value use cases which require hyper-scale. A second difference from classical key/value stores is that ArangoDB is not optimized for blob storage (i.e., binary large objects like image files). We recommend to use a dedicated filesystem to store blobs and ArangoDB for storing the metadata.
Native multi-model provides many crucial advantages for modern & agile application development.
The managed service for ArangoDB, provides fully hosted, managed, & monitored cluster deployments of any size, with enterprise-grade security.
Running any database by yourself takes a lot of work and expertise.
We created Oasis so you do not have to worry about any of that and focus your time and energy on building great applications!

Oasis offers you a fully managed graph database, document store and fulltext search engine.
All in one place.
When your application needs to evolve, you can go multi-model at any time.
Encryption at transit & at rest guarantee all your data is encrypted before it hits the disk or send over the network.
In addition, you can assign fine-grained access control policies to your organization, your projects or deployments. This assigns permissions to groups or individual users.
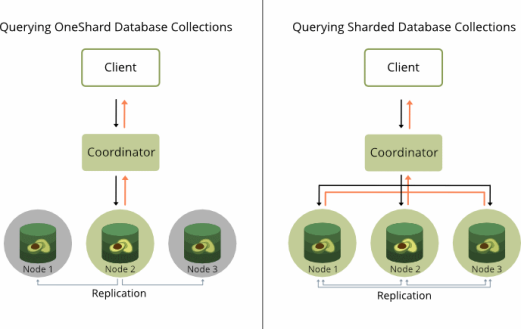
You can elastically scale with all deployment models (OneShard & Sharded Clusters) at anytime and use the special Enterprise features for efficient queries against distributed data.
Completely manage Oasis via a sophisticated API.
Automate Oasis using your preferred language, script it using the oasisctl commandline tool or manage your infrastructure GitOps style using terraform.
Get support by the people who built Oasis and ArangoDBs distributed systems.
You can choose between different support plans for every deployment ranging from good support in the free version to individual expert support with short response times in Oasis Enterprise.

Create as many deployments as you need, scale them elastically any time to meet changing demand and welcome new customers seamlessly.
Arrange your deployments in projects to to mirror development structures within your team or company.
Assign fine-grained user access policies to deployments, projects and individual users to coordinate teamwork while meeting GDPR, CCPA and other regulations. From the first line of code to large organizations, ArangoDB Oasis has you covered.
When building a production-grade machine learning infrastructure, ArangoML Pipeline provides support for common metadata storage.
ArangoDB, with its native multi-model capabilities, is a great match for your machine learning workloads. ArangoML Pipeline is now available as a cloud service - ArangoML Pipeline Cloud.
When building a production-grade machine learning infrastructure, ArangoML provides support for common metadata storage across the entire machine learning lifecycle, and there enables reproducibility, monitoring, and auditing for your machine learning models.
ArangoDB offers support for both analytics tasks and multi-model-powered machine learning. It is particularly helpful when dealing with a mixture of structured and unstructured data as ArangoDB can natively and efficiently manage different data models.
Everyone knows training data is an important prerequisite for training machine learning models. But for building a production-grade machine learning platform, we actually should equally care about another type of data: metadata. Production machine learning platforms consist of a number of different steps and components:

Most of those components produce some kind of metadata including for example references to data sets, and training runs with the associated train and test accuracies, model serving statistics, provenance information linking trained models to the datasets used for training, and many more. Data Scientists and DataOps require common metadata storage to answer questions such as: which model was trained with this dataset, which feature is resulting in the best test accuracy.
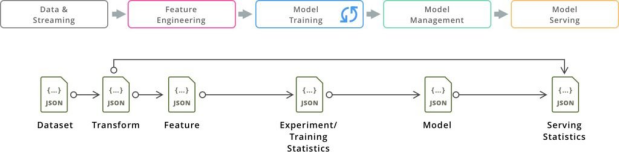
Here ArangoML offers a simple interface for access across your favorite machine learning frameworks and tools.
As ArangoML is backed by the multi-model capabilities of ArangoDB it can store unstructured data such as the training statistics of a particular training run (document) as well as the connection (graph) to the associated dataset and the resulting model. So the queries above basically become a graph traversal.
You can also find the associated code here.
ArangoML Pipeline is a powerful yet simple tool to facilitate teamwork between DataOps and Data Science but allows also to provide detailed audit trails for auditors and advanced analytics of the whole machine learning environment.
ArangoML Pipeline Demo on GitHub
SmartJoins, SatelliteCollections, SmartGraphs, Enterprise Security, Enhanced Data Masking & Datacenter to Datacenter Replication.
ArangoDB Enterprise
The Enterprise Edition of ArangoDB focuses on solving enterprise-scale problems and highly secure work with data. Various features like SmartGraphs or SmartJoins allow lightning fast query execution for graph and relational use cases while 360 encryption, LDAP-integration and Data Masking enable highly secure work with ArangoDB.
ArangoDB Oasis, the Managed Cloud of ArangoDB, supports many Enterprise features like OneShard, SmartGraphs, SmartJoins and Security Features. Get more details and sign up for a 14-day trial.
Together with a feature-rich and fast Java Driver and the SpringData integration, ArangoDB provides a solid yet flexible package to quickly adapt to changing needs.
SatelliteGraphs allow replication of graphs to multiple machines within a cluster for local query execution of queries involving graphs. Optimal solution for using document or time series data in combination with graph queries for analytical and operational needs.

OneShard
Not all use cases require horizontal scalability. In such cases, a OneShard deployment offers a practicable solution that enables significant performance improvements by massively reducing cluster-internal communication.
Datacenter to Datacenter Replication
Run a distributed database in one datacenter and replicate all transactions to another datacenter. Our solution is asynchronous and scales to arbitrary cluster sizes. It is fault-tolerant without a single point of failure.

SmartGraphs
Scale with graphs into a cluster and stay performant. This unique feature enables you to explore entirely new spheres in graph usage and provides nearly the same performance of graph traversals as a single instance setup.
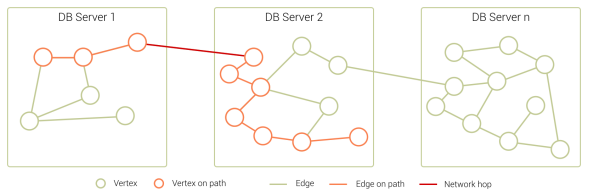
SatelliteCollections
Faster join operations when working with sharded datasets. Avoid expensive network hops with collections replicated to each machine to allow local joins.

SmartJoins
SmartJoins are a solution for running fast distributed JOIN operations against sharded collections by utilizing a smart sharding scheme allowing to JOIN operations with minimal network traffic.

Enterprise Security
Safeguard your data with additional high-security features: Auditing, Encryption at rest, LDAP integration and Encrypted backup.
Enhanced Data Masking
Safeguard sensitive user data by creating obfuscated exports when working in environments posing a risk of data leak.
Natively integrated cross-platform indexing, text-search and ranking engine for information retrieval, optimized for speed and memory.
Powerful Search Included
ArangoSearch is a powerful search and similarity ranking engine natively integrated into ArangoDB. Combine search with any other data model.
Feature-Rich, Accurate & Ranked Search
Perform highly efficient search with C++ based ArangoSearch. Use many query types spanning phrase, wildcard, proximity, range and much more. Rank your results by similarity using BM25 or TFIDF algorithms.

Provide Search for Everyone
ArangoSearch supports already 30 languages including English, most european languages and also Chinese. Use dedicated language analyzers, stemming and stopword removal for fast and efficient search in all supported languages.
Find Relevant Results to Fuzzy Searches
Provide highly relevant results for your users despite typos and other non-exact matching. Fuzzy search in ArangoSearch lets you use ngram and Levenshtein algorithms to find the best approximate results. Great for supporting search in mobile, scientific, bioinformatics and many other use cases.

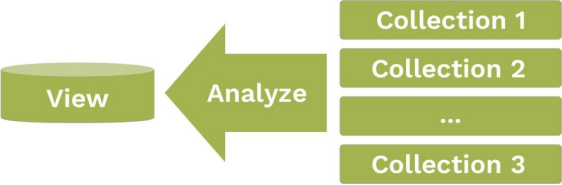
Search Across Multiple Sources
Perform complex searches including multiple attributes and data collections in ArangoDB. Unite your data sources in an ArangoSearch view for fast results to even complex queries.
Perform Multi-Model Graph Searches
Extend your ArangoSearch queries with graph, geo or relational-type aspects for even more fine-grained access to your data. The flexibility of native multi-model combined with search is a powerful companion for many projects and simplifies your deployment stack
Index Everything
ArangoSearch supports schema-agnostic indexing for allowing maximum flexibility within your search queries. Combine even complex search across attributes & collections with all supported data models in ArangoDB.

ArangoDB Oasis is the simplest way to run ArangoDB. Oasis runs ArangoDB Enterprise including all unique features for optimal performance at any scale
AQL provides a powerful way to access and combine all data access strategies in ArangoDB.
Unify your data storage logic, reduce network overhead and secure sensitive data with Foxx.
Enrich your graph, document or search queries with geo-locational aspects.

© Copyright 2000-2025 COGITO SOFTWARE CO.,LTD. All rights reserved
