High-Level Overview
Nagios Log Server is an application that provides organizations a central location to send their machine generated event data (e.g., Windows Event Logs, Linux syslogs, mail server logs, web server logs, application logs) which will index the content of the messages, and store the data for later retrieval, querying, and analysis in near real-time.
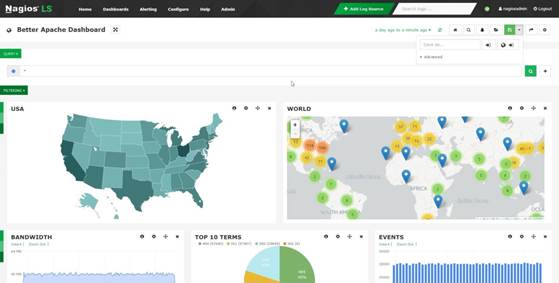
Once log data has been indexed (indexing usually happens within 5 seconds from arrival) it can be easily analyzed using the graphical query and filtering tools on the dashboard. Log Server includes a quick search utility which will search for any log event item on Google, Bing, or Stack Overflow. Alerts can be created based on a query, and are able to be sent via email to users of your choice. Alerts can also be sent to Nagios XI/Nagios Core via NRDP, send a SNMP Trap, or even start a custom script.
The data that is sent to Nagios Log Server can be automatically archived to a shared network drive. The archived data can be restored and re-analyzed at any point in the future.
What that means in plain English is that it can be used to record any log events that are happening across all of the machines and network devices organization-wide. Users of Log Server can access all of this data in a central location, searching it through the UI. Having all of the data in one location has the benefit of being able to compare or correlate log data from multiple devices. Also, the automated archiving of the log data will assist in maintaining compliance with certain standards which require log data to be stored for various amounts of time.
Most Common Use Case
Less Common Use Cases
The Benefits of Nagios Log Server Over Text-Based Systems
Nagios Log Server allows all of your organization's machine generated data to be stored and indexed in one central location, allowing for queries to be performed on all of the log data at the same time providing the ability for correlative analysis. Additionally, this data can be presented to the user running the query in customized views called dashboards, including a table of results, bar charts, pie charts, line graphs, etc. for any of the fields of data. Additionally, fields in the logs that are determined to be numeric can have calculations done when creating/using the graphing/table functionality to provide data like total, min, max, mean, etc.
Important Terms and Vocabulary
Nagios Log Server is a combination of three different open-source components: Elasticsearch, Logstash, Kibana. (ELK)
Elasticsearch: The scalable and redundant datastore used by Log Server.
Logstash: The log receiver for Log Server – Logstash outputs logs to the Elasticsearch database.
Kibana: The visualization component of the ELK stack – it is used to produce dashboards, made up of tables, graphs, and other elements.
How Nagios Log Server differs from the ELK stack
Understanding Elasticsearch
Elasticsearch is a transparent component – it does not need a lot of tuning, especially if your cluster is small.
Elasticsearch is the database of choice because it is distributed and redundant by default. Every time an instance is added to your cluster, Elasticsearch ensures that its database is spread across all nodes appropriately by moving around the various shards in a manner that increases the resiliency of the data.
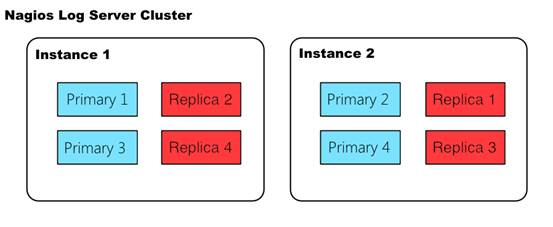
In the above picture, there are two instances joined in a single cluster. Each instance contains two primary shards (colored blue) and two replica shards (colored red). Note that Elasticsearch will never assign a matching primary shard and replica shard to the same instance, which is how high availability is achieved.
Understanding Logstash
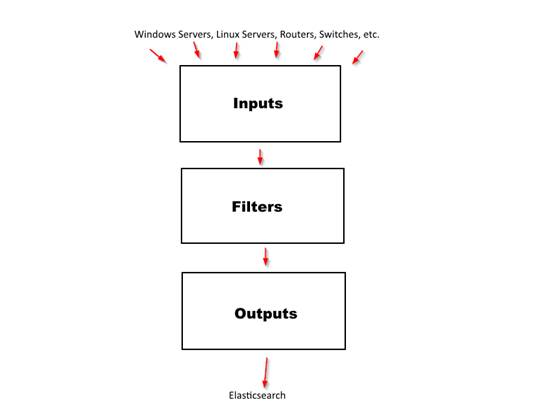
Logstash is the most complex component in Nagios Log Server that an administrator will have to deal with. It is imperative that a good understanding of logstash is developed. The logstash agent is a processing pipeline with 3 stages: inputs -> filters -> outputs. Inputs receive incoming logs, and pass those logs to the filter chain, filters modify them, outputs ship them elsewhere - in our case, to the elasticsearch database.
Inputs
Inputs listen for incoming logs. The three most common inputs by far are TCP, UDP, and syslog. The tcp input will listen on a specified TCP port, and accept any logs coming in on that port. The UDP input will do the same, but it will listen on a UDP port. The syslog input is where things get a little more complex - every log that comes into the syslog input will automatically have the 'syslog' filter applied. For reference, the syslog filter is a simple grok filter that looks like this:
"match" => { "message" => "<%{POSINT:priority}>%{SYSLOGLINE}"
Filters
Filters are the most complex and important part of the Logstash chain. If you spend time learning anything, learn filters. It will help if you have a background in regular expression. Regular expression syntax doesn't take very long to learn, and it is tremendously helpful when generating your own filters. There are many free tutorials online to learn from.
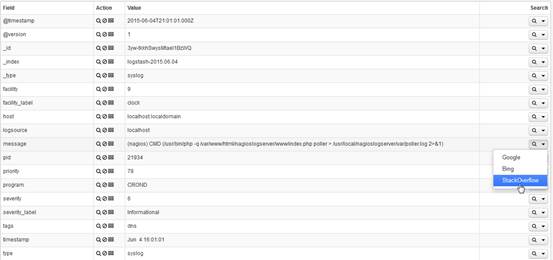
Logstash filters parse logs passed down from the input chain to 'filters' that you define. Before filters are applied, your logs are likely unstructured and have no 'fields' applied to them. After filtering, you might see fields like the following.
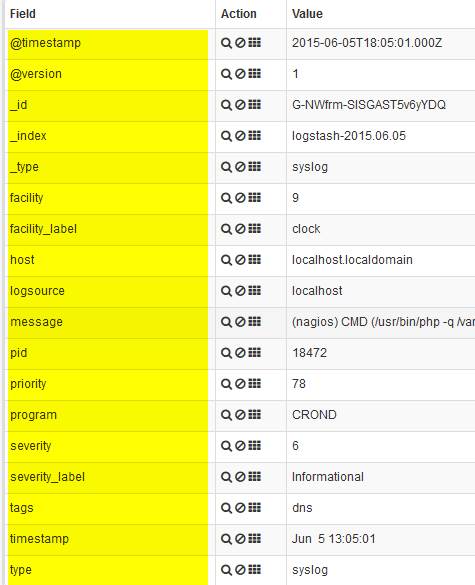
Fields are important because they enable the creation of graphs and visualizations:
Outputs
Outputs allow you to send the log data externally, this is a more complicated topic and is not required for Nagios Log Server functionality. The following documentation demonstrates how an output can be created:
Documentation - Using An Output To Create Nagios XI Passive Objects

© Copyright 2000-2026 COGITO SOFTWARE CO.,LTD. All rights reserved
