
How Refinitiv Built a ‘Single View of Everything’ BA/BI Platform
Technology continues to transform businesses. We at Refinitiv have sought to use technology to make information that we gather in the course of our business more relevant and more personal, as well as deliver it faster to our clients and employees. By using shared platforms and working across our business units, we want to make our data more accessible and insightful for our people, no matter how they might access it.
To facilitate this approach, we wanted to create a sophisticated Business Analytics and Intelligence (BA/BI) platform providing a single view of everything for all Refinitiv employees. This was quite a challenge as we would have to integrate many different data sources containing semi-related data in different structures, so as to serve a variety of needs and requirements of several departments and roles.
For data access and management, it became clear that we would need a fast, schemaless data storage to deal with the growing amount of unstructured data in our BA/BI application. Our application made use of more than twenty data sources, providing a variety of information. This called for a powerful query language capable of expressing a broad spectrum of questions to which our employees would want quick answers.
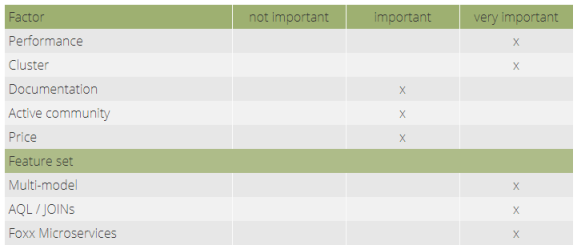
A key requirement was to support ad hoc joins, as well as graph traversals to use the right data access strategy for the different parts of applications, and being able to ask more questions. Our preference would be an open-source solution with an active and responsive community.
First, ArangoDB is a true open-source project with a developer-friendly, Apache 2 license. Plus, we felt that the team behind it is helpful and transparent. After a rather short adjustment phase, we were addicted to the ArangoDB Query Language (AQL). For us, it’s pretty intuitive to write queries, and we can leverage a broad variety of functions and data access patterns. The spectacular aspect of AQL is that it uses nested FOR loops to compose queries. As a result, the transition between writing code and writing queries with AQL was much smoother. Their multi-model approach and the possibility to have joins and graph traversals natively in AQL is very good. Sometimes it’s handy to combine joins and traversals in the same query.
Another significant plus of ArangoDB is the microservice framework, Foxx. We use it fairly intensively; we’ve created more than twenty Foxx services for our application. Frankly, getting started with Foxx was a bit rough: the documentation could be improved and more examples or best practices would be helpful. At the moment, though, this difficulty is minimized by the ArangoDB team and excellent community support. They are extremely responsive and professional. This was one of the reasons we decided to use the database system.
Currently, we store a little over 270GB of data in ArangoDB (dumped to disk 408GB). As the amount of data grows steadily, we will soon move to a three-node cluster, primarily for high availability reasons (see image below).

The setup for our current single node setup is 24 vCPUs and 512GB of RAM. For the cluster setup we plan to use the same machines for the masters.
Our application itself is read/write intensive, with a minimum of three writes per second and two-thousand updates per second during peak times. The queue in our architecture helps with shadow writes and to even loads on ArangoDB. Reads are generally steady; we don’t anticipate massive spikes.
First of all, we learned that it is actually possible and sometimes very helpful to combine different data models in a query. Queries run very fast and AQL is so intuitive to learn that even our Product Owners and Business Analysts are now writing huge queries, some more than two-hundred lines long, with relative ease. Sometimes they have to ask which index should be used, but most queries run with acceptable performance and without much additional effort.
The Foxx framework helped us to reduce greatly our development time. As we would integrate with many REST services, we used to write plenty of simulators for integration tests. Now mocked REST services can be spinned instantly with Foxx. We can define our own routes so that actual data doesn’t have to be sent to the client. Instead, it can be processed within the database itself and only the results are sent to the client. By this method, we can reduce much of the hassle, as well as improve our security when needed. For us, Foxx with ArangoDB is a great help and pretty awesome to use.
In general, we can now have all of the data we need—assurance, reporting, mobile, API portal—in one place, providing fast and secure access. The flexibility of AQL, and the combination of the different data models, make it easy to get needed queries running and optimized. Extending the functionality of our application is now very smooth thanks to Foxx and AQL. As a result, we could spend more time on the actual application development, and get more quickly the answers we need. After all, we are known as The Answer Company.
A very big thanks to Tanvir for taking the time to share his experiences with the community!

© Copyright 2000-2026 COGITO SOFTWARE CO.,LTD. All rights reserved
